

Dürfen wir Sie beraten?
Norbert Kytka
KontaktSAP Analytics Blog
Welcher Webseitenbesucher schließt eher den Kauf ab, wenn eine Ware in den Warenkorb gelegt wurde? Der, dem man möglichst gute Zusatzvorschläge macht und den man zu vielen zusätzlichen Klicks verleitet? Oder der, der ohne weitere Störungen gleich den Checkout-Prozess abschließen kann?
Um die Antwort auf diese Frage zu bekommen, haben wir einen spannenden Test gestartet: Wir haben einen 110 Millionen Zeilen starken Datensatz eines E-Commerce-Shops unter die Lupe genommen – mit einem Mix aus SAP-Tools, Machine-Learning-Verfahren, die in der SAP HANA Cloud integriert sind, und Non-SAP-Tools. Ein Shop-Betreiber könnte so eine Datenauswertung gut gebrauchen, damit er weiß, welches Ziel er bei einem Optimierungsprojekt verfolgen sollte: Aktivität der Kunden fördern oder den Check-out vereinfachen.
Wie gut sind SAP Analytics Cloud, Data Warehouse Cloud und als darunterliegende Datenbank HANA Cloud? Ist SAP HANA Cloud geeignet, in Kombination mit Non-SAP-Technologien die entsprechenden Auswertungen zu erstellen? Und wenn ja: Wie mühsam ist der Weg dahin? Erlauben sie eine schnelle Datenintegration? Können wir bei der Datenbeschaffung, -vorbereitung und -transformation Machine-Learning-Verfahren einsetzen? Wie gut funktioniert der Zugriff auf die Daten mit einem Open-Source-Werkzeug wie dem hier eingesetzten Jupyter Notebook – und kann man darin die Libraries von SAP HANA tatsächlich nutzen?
Und so sah unser Set-up aus: Die Business Technology Platform (BPT) der SAP SE erlaubt uns die Nutzung der SAP HANA Cloud als Datenbankinstanz sowie den Zugriff auf die dortigen HANA-ML-Bibliotheken. SAP HANA Automated Predictive Library (APL) und SAP HANA Predictive Analysis Library (PAL) sind in der SAP HANA Datenbank eingebettet und damit verfügbar in der SAP HANA Cloud. Der Zugriff auf die Libraries mittels Jupyter Notebook ist durch den in SAP HANA integrierten Python Client möglich. Die Data Warehouse Cloud ist unser Werkzeug für die Datenanalyse und
-modellierung, SAP Analytics Cloud das Tool für die Visualisierung und die Report-Erstellung.

Für diesen Test arbeiteten wir mit zwei unterschiedlichen Workflows. Bei dem ersten testeten wir, wie sich die Daten erschließen lassen, wenn sie sich in der SAP HANA Cloud befinden und über das Jupyter Notebook angesteuert werden. Bei dem zweiten lagen die Daten in der Data Warehouse Cloud und wurden mit dem Jupyter Notebook genutzt. So konnten wir einen Eindruck gewinnen, wie das Zusammenspiel der SAP- und der Non-SAP-Lösungen funktioniert, wenn – wie im ersten Workflow – Daten nur aus SAP-Systemen genutzt werden. Viele Unternehmen verfügen über Datenschätze, die nicht in SAP-Systemen liegen. Im zweiten Workflow konzentrierten wir uns daher darauf, herauszufinden, wie unser Set-up funktioniert, wenn die Daten aus unterschiedlichen Datenquellen stammen.

Um die grundlegenden Funktionen der HANA ML Features zu verwenden, ist es wichtig, bei der Konfiguration der HANA Cloud Datenbankinstanz mindestens 3vCPUs zu nutzen, Verbindungen von Ihrer IP-Adresse zuzulassen und den Scriptserver, auf dem die HANA ML Libraries liegen, zu aktivieren. Die CSV-Dateien werden in ein eigens dafür angelegtes Schema in der SAP HANA Cloud abgelegt.
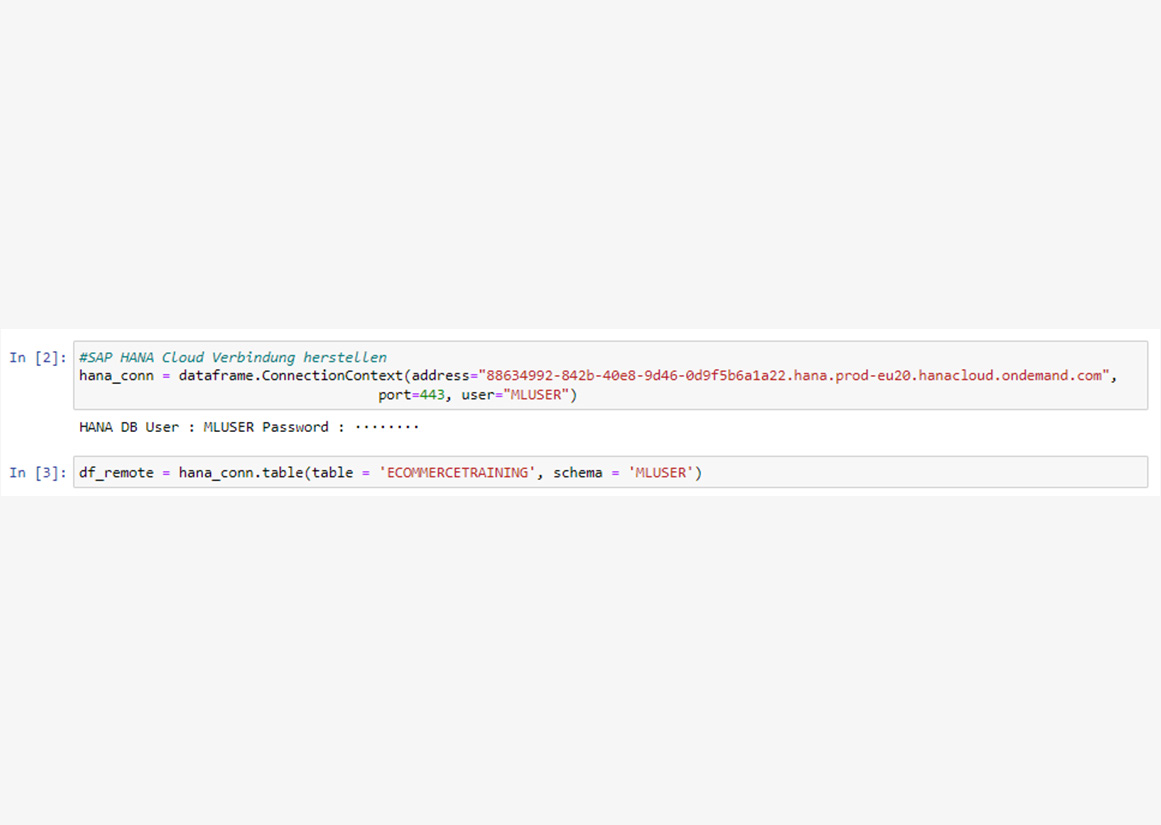
Nach Installation der hana-ml Python API können die Funktionen der einzelnen Libraries genutzt werden. Mit der Funktion ConnectionContext kann eine Verbindung zur HANA Cloud oder auch zur DWC hergestellt werden - je nach Anwendungsfall. Weiter wurde ein ML-Modell mit den verfügbaren Funktionen erstellt. Nach Beendigung der Lern- und Testphase werden die Ergebnisse in die HANA Cloud übertragen.
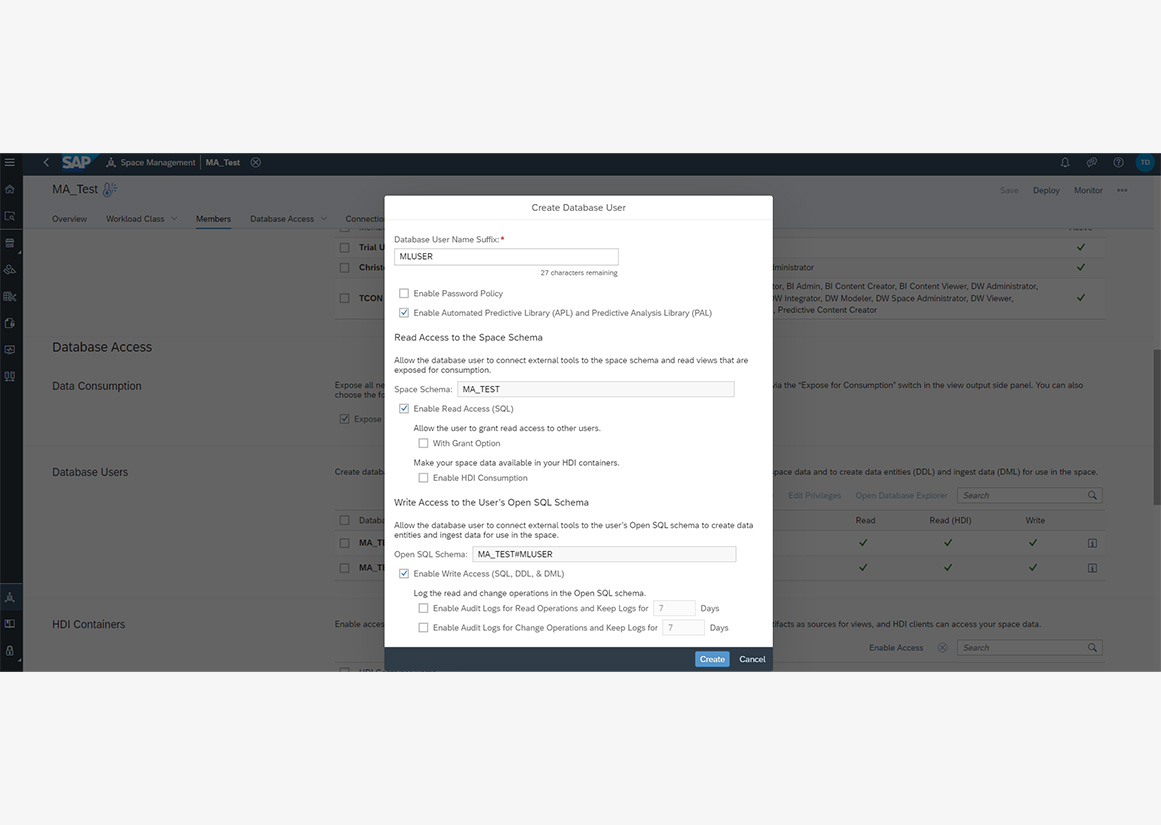
In der DWC wurde ein extra Arbeitsbereich für die Datenmodellierung der ML-Ergebnisse erstellt. Wenn ein direkter Datenzugriff auf Daten in der DWC mit Jupyter Notebook erfolgen soll, ist es - je nach Workflow - außerdem wichtig, einen Datenbankuser im Space zu erstellen. Dabei gilt zu beachten, dass die Libraries PAL und APL aktiviert sind.
In der DWC werden die Daten im Data Builder, je nach Bedarf, für das Reporting modelliert. Die Daten aus der HANA Cloud lassen sich einfach integrieren, indem eine Verbindung zur HANA Cloud angelegt wurde. Die Daten liegen somit auf der HANA Cloud und werden nicht persistent in der DWC gespeichert.
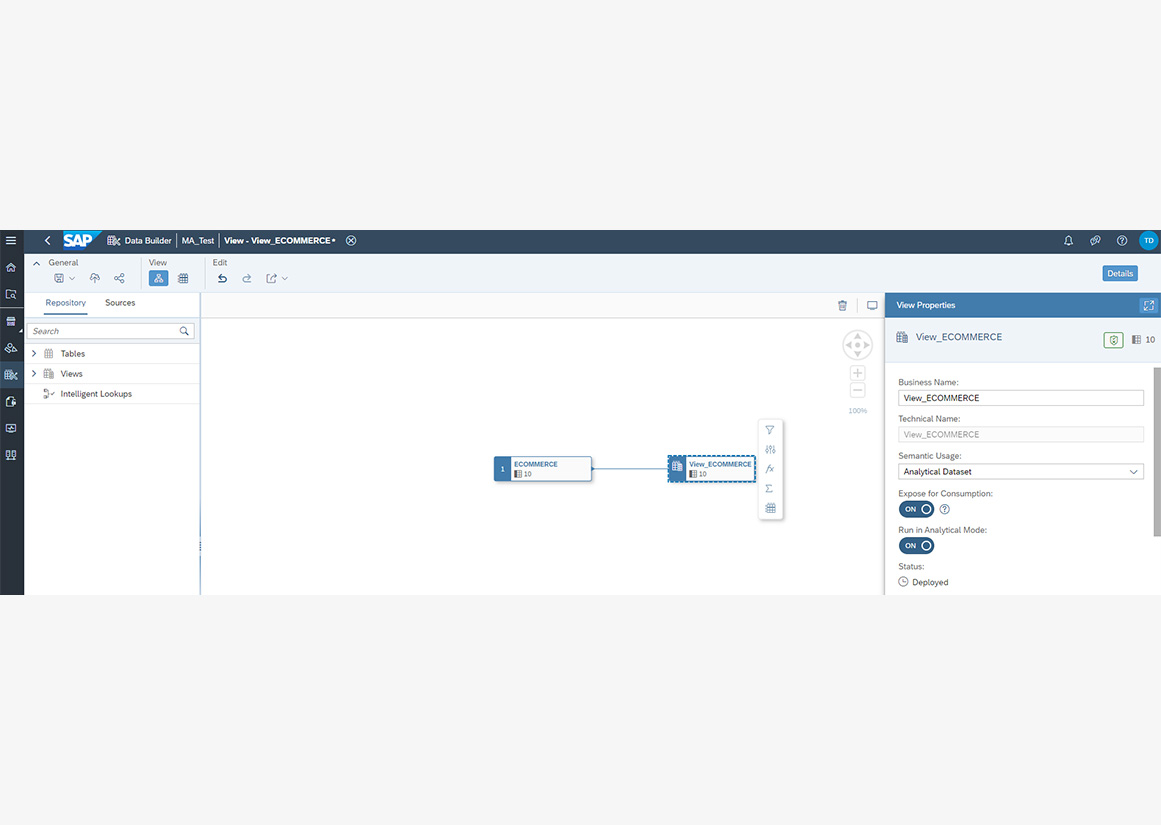

Durch die Integration der SAC in der DWC kann einfach auf die modellierten Daten zugegriffen werden und weiter in der SAC verwendet werden um ein Reporting zu erstellen.
Eines haben wir bei der Arbeit mit diesem Set-up gelernt: Beim Zusammenspiel von SAP- und Non-SAP-Tools sind viele Technologien und Konnektivitäten im Spiel. Ihr Zusammenspiel sauber zu orchestrieren, erfordert eine gewisse Geduld und Sorgfalt. Wir können nun aber mit Bestimmtheit sagen, dass wir die Technologien sicher beherrschen und schnell zu Ergebnissen kommen.
Das liegt auch daran, dass die Technologien, die wir nutzen, für sich genommen alle eine gute Reife besitzen. Der Zugriff auf Machine-Learning-Verfahren ist mittels BTP und DWC kein Problem - im Gegenteil: Es geht, und es geht einfach. PAL und APL bieten eine Vielzahl von Algorithmen und werden bereits als integraler Bestandteil der SAP HANA Cloud ausgeliefert.
Zugleich ist die Technologie der SAP SE inzwischen so offen, dass sich ohne Weiteres der Zugriff auf die SAP HANA Cloud mit einem Open-Source-Werkzeug wie dem Jupyter Notebook einrichten lässt. Die Daten, die man auf diesem Weg nutzbar macht, können leicht in DWC und SAC genutzt werden. Das war bei diesem Szenario beim Erschließen des E-Commerce-Datensatzes und seiner anschließenden Auswertung der Fall.
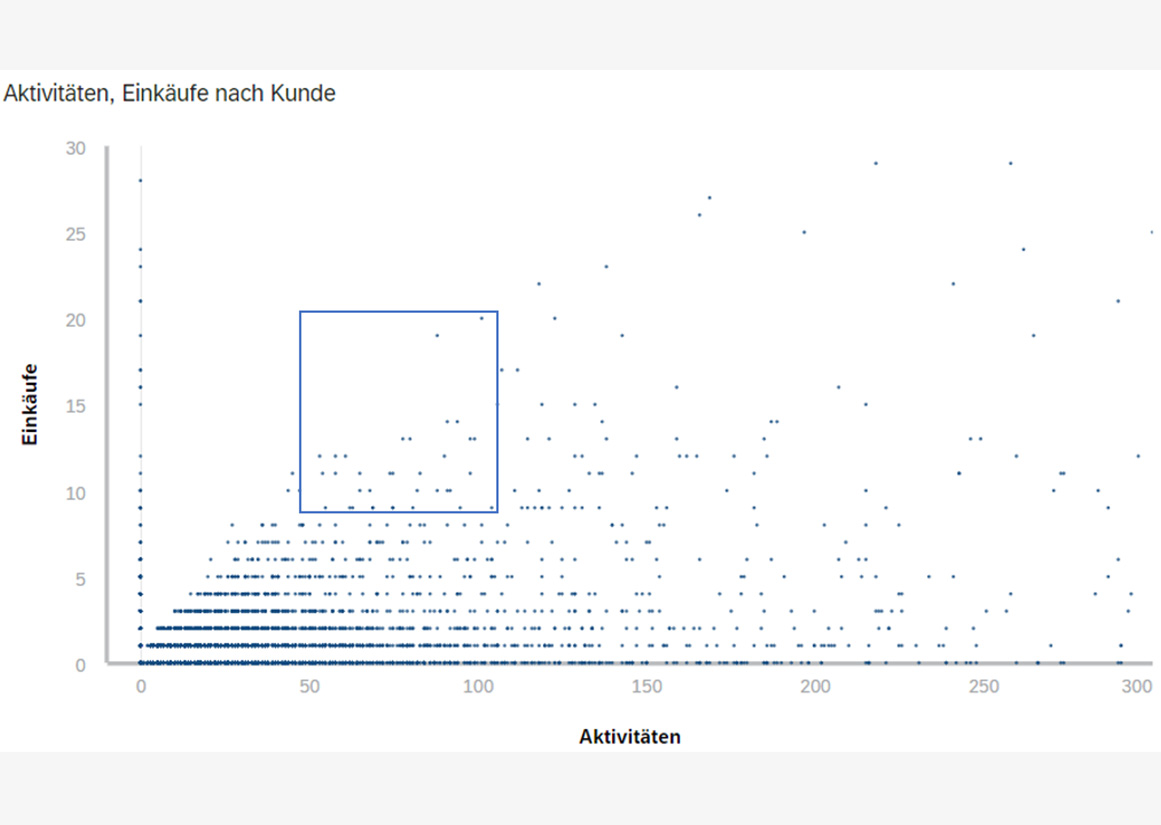
Tatsächlich gelang es uns, bei diesem Vorhaben mit unserem Set-up zu einem Ergebnis zu kommen und die Eingangsfrage zu beantworten. Wäre ein echter Store-Betreiber unser Kunde, hätten wir sein Augenmerk auf die Aktivität der Kunden als wichtigsten Faktor gelenkt, an dem man vorhersagen kann, ob ein Kunde den Kauf abschließt, wenn er schon eine Ware in den Warenkorb gelegt hat. Die Visualisierung zeigt, dass einige Kunden die keinerlei weiterer Aktivitäten rund um die Transaktion und den Warenbestand machten, direkt über den Checkout-Prozess einkaufen, jedoch die meisten Kunden mehr Einkäufe tätigen umso mehr Aktivitäten sie im Onlineshop durchführen.

Das bedeutet: Der Store-Betreiber kann die Wahrscheinlichkeit für Kaufabschlüsse steigern, indem er die Aktivität seiner Kunden auf der Seite und rund um den Kaufprozess steigert. Welche Maßnahmen genau dazu geeignet sind, wäre in einem Folgeprojekt neu zu definieren. Das könnten das Einblenden guter weiterer Produktvorschläge, der Hinweis auf Discounts und Gutscheine, das Anzeigen von Feedback-Elementen und Dialogen, der Verweis auf Loyalitätsprogramme oder andere Instrumente aus dem E-Commerce-Werkzeugkasten sein.
Klar ist auf jeden Fall: Der Store-Betreiber würde weniger Abschlüsse machen, wenn er dafür sorgt, dass Kunden den Checkout-Prozess schneller als bisher abschließen können und damit im Endeffekt die Webseite schneller verlassen. Ziel seiner Optimierung sollte sein, dass die Kunden aktiver auf der Seite sind und dadurch mehrere Einkäufe abschließen.
Für uns war es aufregend und spannend zu sehen, ob wir mit unserem Instrumentenmix tatsächlich zu aussagekräftigen Ergebnissen kommen. Das deutliche Ergebnis, aber auch die Tatsache, dass die genutzten Technologien so gut miteinander zusammengespielt haben, bestärkt uns in unserer Ansicht, dass einerseits unser Technologie-Know-how wirklich etwas Besonderes in diesem Bereich ist. Andererseits bieten die technologischen Möglichkeiten rund um die neuen Cloud- und Analytics-Produkte der SAP SE fantastische Möglichkeiten, auch sehr komplexe Fragestellungen mit Hilfe modernster Innovationen für unsere Kunden zu beantworten. Welche Aufgaben Sie für uns haben – darauf sind wir gespannt.

Haben Sie Fragen zu diesem Thema? Dann kontaktieren Sie mich gerne.
Stefan Schwenzl | Business Lead SGF Analytics | analytics.experte@team-con.de